
When talking about software design architecture, there are many principles, best practices, tips, design patterns, code review and quality control workflows, object-oriented design methodology, top down design, stateful and stateless design and so on. The final goal is to achieve high quality, reusable, manageable, most test covered, extensible software release, no matter which language is used to code the software: C/C++, Java, Python, Go and so on.
So, if I am asked to name the two most import software design principles during all those to achieve this goal, here is my choice:
Principle 1: Plug in Architecture
No matter you design a device driver, a high-level function block and so on, think about the abstraction layer at first, to separate function APIs and how those APIs are finally realized and implemented by different underline code. First, you need to well define all the APIs which your function block and drivers will provide to the user of your component. You can abstract the APIs using technology such as function pointers in C/C++, and then plug in or bound the detailed implementations of those APIs later. This kind of plug in can be static, i.e. at software initialization time or can be dynamic, i.e. at system rebooting time to dynamically finds the different and suitable implementations of those function pointers for the platform your driver or code will be used and plug those specific backend implementations accordingly, as illustrated in following diagram:

For example, you need to abstract out the dependency of your software functions with a specific platform specific function implementation. You can first define the API of your software component, during your software initialization phase, on platform 1, you plug in this platform’s detailed implementation to this API’s function pointer. On platform 2, you plug in platform 2’s detailed implementation of this function pointer. For the user of your software component, its APIs keep unchanged and the software components using your software do not need to be rewritten and re-tested.
This principle is widely used not only in software design, but also in other technologies, such as OpenStack ML2 plugin design architecture for Neutron, Opendaylight SDN controller plugin architecture, Kubernetes external device plugin framework architecture to extend Kubernetes design by using gRPC registration for support features like PCI device pass through without the need to change the Kubelet design itself and so on. Kubernetes was originally built to orchestrate Docker containers. Kubernetes 1.5 introduces the Container Runtime Interface (CRI) concept, an API architecture which can be used to adopt any container runtime that follows the CRI standard. By this, Docker, containerd, CRI-O, and other can all works with Kubernetes under one unified architecture.
Principle 2: Event Driven with State Machine
In this principle, you figure out the finite states of your software component, define the state machine and events which can cause the transition between those states and use those information to define and realize your software APIs, as shown in following diagram:
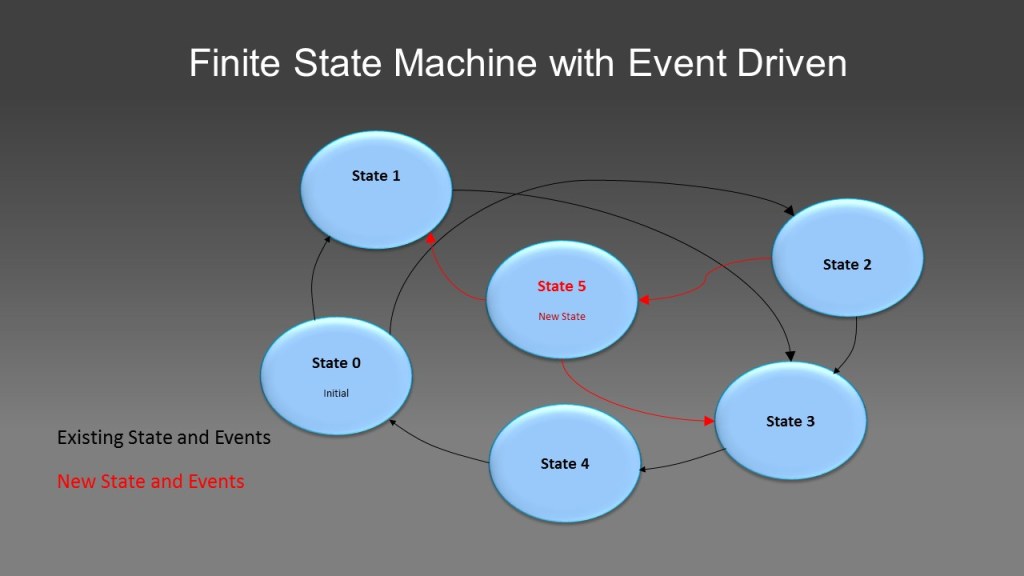
The blue color states and black arrows represent your initial software states and events, which your software can be and the events can cause state transition between those. You coded those and according state transit handling codes and are well coded, reviewed and documented. Let’s say there is a new state: state 5 and its according events are discovered or needed later, those are represented by red color. With this design principle, you just need to add this new state into your state table, add handlers to the new events and you are done. All existing codes handle existing software states and events remain unchanged and re-testing is not needed. By this way, you extend the functions of your software without impacting your existing software functions and reusing existing software functions.
This principle is also widely used in device driver, FPGA, hardware function design field.
